Na začátku července jsem se rozhodl udělat průzkum českého internetu, abych zjistil, kolik webů není správně nakonfigurováno a má povolen přístup ke složce .git s repozitářem verzemi souborů. Z minulých průzkumů jsem měl ve své databázi mnoho webů, kde jsem tento problém detekoval, a tak mne zajímalo, jaký je skutečný stav. Průzkum se nakonec rozrostl na celý internet.
Jedná se o poměrně ošidný problém, kdy je možné získat současné i minulé soubory webu a vydolovat z nich mnoho informací o struktuře webu samotného a někdy i velmi citlivá data, jako jsou hesla k databázím, API klíče, nastavení vývojového prostředí a podobně. Podle best practices by samozřejmě v repozitáři žádná taková data být neměla, nicméně při minulých bezpečnostních scanech jsem se přesvědčil, že mnoho tvůrců tato doporučení nedodržuje.
Nejprve se podíváme, jak se problém projevuje. Pokud používáte git k deploymentu svého projektu, tak byste složku .git neměli mít ve veřejně přístupné části webu. Pokud ji tam z nějakého důvodu opravdu mít musíte, je třeba zajistit, aby k ní byl blokován přístup z vnějšku. Ověřit si to můžete lehce tak, že zkusíte otevřít adresu <vas-web>/.git/HEAD - pokud máte vše správně nastaveno, tak by to nemělo jít. Záludnost této zranitelnosti spočívá v tom, že ji lze lehce přehlédnout. Pokud totiž navštívíte pouze adresu <vas-web>/.git/, dostanete v naprosté většině případů chybu 403 - přístup odepřen. Na první pohled se tak může zdát, že blokace funguje, jedná se však o falešný pocit bezpečí. Pravda je ale taková, že chybu 403 způsobí neexistence souboru index.html nebo index.php a to, že máte zakázán výpis adresářů (autoindex). Přímý přístup k jednotlivým souborům může být však stále možný. Pokud se vám při tomto druhém testu zobrazí adresářová struktura, je problém ještě horší, repozitář lze stáhnout opravdu velmi lehce a navíc může být dohledatelný na Google. Git repozitář má známou strukturu, a tak z něj lze jednoduše získat jednotlivé známé soubory a extrahovat z nich reference na jednotlivé objekty/packy repozitáře a ty následně přímo postahovat. Tímto způsobem jde většinou zrekonstruovat velkou část repozitáře. Pro rekonstrukci existují nástroje, které tuto činnost značně zjednoduší - GitTools.
I bez náročné rekonstrukce se může podařit získat o webu mnoho informací. Z binárního souboru <vas-web>/.git/index lze například odvodit struktura aplikace - jaké používá knihovny, najít zajímavé endpointy (např. file uploadery) atd. Pokud vás nebaví hledat řetězce přímo v binárním souboru, existuje pomocník, který vám ho dekóduje - Gin.
Samozřejmě existují výjimky, kde přístupnost repozitáře nevadí: weby, které celý svůj obsah již veřejně sdílí například na GitHubu, nebo weby složené pouze z několika statických souborů. Nicméně i v těchto případech si myslím, že by přístup k souborům a složkám začínajících tečkou (s výjimkou .well-known) neměl být možný. Připravil jsem proto několik pravidel pro webové servery Nginx a Apache, které přístupy ošetří.

Vraťme se k samotnému scanu. Začal jsem stejným způsobem, jakým provádím většinu svých scanů - sestavil seznam webů ke kontrole, napsal scanovací skript (Python, Requests, Concurrent.futures + ThreadPoolExecutor), zpracoval výsledky a upozornil dotčené weby.
Postup:
- seznam - ze svých předchozích průzkumů mám již poměrně obsáhlou databázi českých webů - sestavil jsem ji pro Průzkum českých WP a z velké části jsem se o ni podělil v repozitáři Michala Špačka. První bod vyřešen - zhruba 1,5 milionu domén ke zkoumání.
- skript - skripty z předchozích scanů jsou vcelku podobné, upravil jsem je tedy tak, aby hlídaly přítomnost souboru /.git/HEAD, kde se v obsahu vyskytuje řetězec refs.
- výsledky - za necelé 2 dny jsem nalezl 1925 českých webů s přístupným .git repozitářem a na malém kontrolním vzorku jsem ověřil, že se jedná opravdu o problém - nalezl jsem jak hesla do DB, tak neautentifikované uploadery.
- kontakt - posledním krokem bylo dohledat kontakty a oslovit je, to je vždy nejnáročnější část, hlavně když máte téměř 2000 webů...
Vzhledem k velkému číslu webů je třeba prioritizovat - když je chyba na velkém známém webu, dopady mohou být mnohem horší než v případě malé zapomenuté stránky. Můj postup nemusí být úplně fér, neboť pro tyto případy mám osvědčený proces - nechám pomocí skriptu se selenium browserem udělat screenshoty všech webů a následně si s nimi "zahraji hru" v prohlížeči obrázků se Steam Controllerem, kdy vybírám weby, které by bylo vhodné kontaktovat.
Přednostně se jedná o následující:
- známé weby (velké riziko, že problém postihne mnoho návštěvníků)
- vývojáři a webové agentury (riziko, že chybu udělali i u svých klientů a když se o ní nedozví, tak ji budou dále opakovat)
- zajímavé weby "páchající dobro"
Takto jsem byl schopen weby roztřídit během zhruba jedné a půl hodiny. Dále bylo potřeba dohledat kontakty - to je většinou ruční práce s nejistými výsledky, protože se e-mail často nedostane ke kompetentní osobě. Tímto způsobem jsem dohledal a kontaktoval prvních zhruba 200 postižených webů. V tento moment jsem si však uvědomil, že to lze u tohoto konkrétního problému udělat mnohem lépe, protože v souboru /.git/logs/HEAD je seznam commitů (příspěvků) do repozitáře. Seznam většinou obsahuje i kontakty přímo na vývojáře, kteří commit provedli, ačkoli ani zde není zaručena 100% úspěšnost, protože někdy jsou použity interní nebo nevalidní adresy. Každopádně to je skvělý prostor pro další automatizaci. Napsal jsem tedy další skript, který získal kontakty na vývojáře a následně je kontaktoval.
Nový postup měl velký úspěch. Velmi jednoduše jsem rozeslal téměř 2000 upozornění relevantním osobám. Měsíc po odeslání upozornění jsem provedl kontrolní scan a otevřených .git zbylo pouze 874 - to je velmi dobrá 55% úspěšnost.
Rozhodl jsem se tento postup zopakovat také pro Slovensko.
- seznam - použil jsem seznam domén, které poskytuje přímo SK-NIC
- skript - skript z předchozího scanu jsem lehce upravil pro získávání e-mailů
- výsledky - za necelý den jsem nalezl 931 webů s otevřeným gitem
- kontakt - automaticky jsem rozeslal upozornění na získané emaily
Jednoduché!
Po druhém scanu jsem začal mít vyšší ambice. Když je takto jednoduché proscanovat 2 státy, jak těžké může být oscanovat celý svět?
Odpověď je - velmi těžké.
Prvním úkolem bylo získat seznam domén pro testování. Část jsem jich měl z předchozích scanů (např. z Alexa Top Million - stažení), pro globální scan to však nestačilo. Bylo třeba vytvořit nový zdroj. Nebylo to poprvé, kdy jsem sáhl po logu DNS dotazů z projektu OpenData Rapid 7. Jedná se o 3,5 TB velký textový soubor ve formátu JSON, kde jsou uvedeny jednotlivé dotazy:
{"timestamp":"1530259463","name":"<domain>","type":"<a/cname/mx/..>","value":"<ip>"}
Díky tomu, že jsou v Linuxu běžně dostupné nástroje pro práci s gzip (zcat,…), nebylo zpracování taktového množství dat velkým problémem.
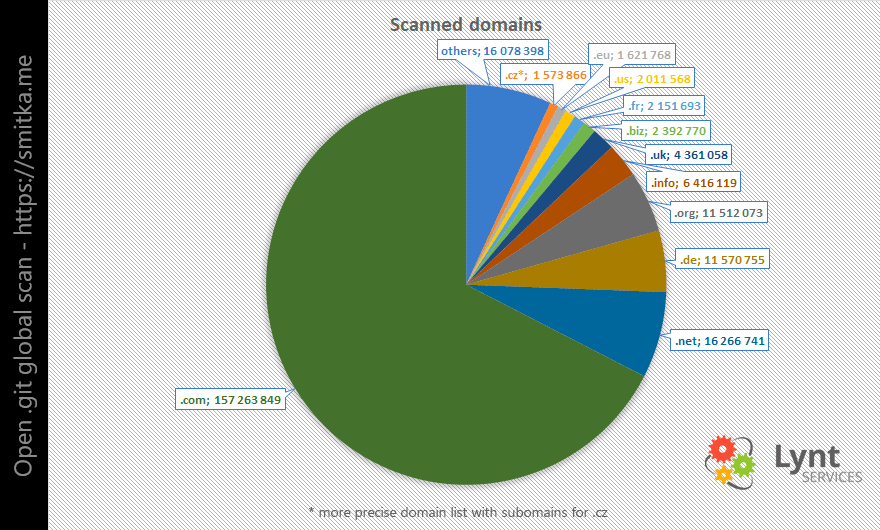
Aby výzkum netrval několik let, bylo nutné provést redukci a vybrat si pouze "zajímavé" domény. Filtroval jsem tedy pouze A dotazy na domény druhého řádu vybraných koncovek (generické, evropské státy +.eu, další větší státy, oblíbené nové koncovky: top, xyz atd.). Takto jsem sestavil seznam více než 230 milionů domén ke kontrole.
Od počátku bylo jasné, že bude třeba úkol rozdělit na více serverů. Seznam jsem tedy rozdělil do bloků po 2 milionech domén. Připravil jsem malou aplikaci v PHP, která dokázala postupně vybavovat bloky jednotlivým serverům a zaznamenávala, jaký server si jaký blok převzal. Servery si pak bloky stahovaly automaticky.
Velmi brzy se ukázalo, že knihovna Requests pro tento účel nebude ta pravá. Prvním problémem bylo nastavování timeoutů - Requests umí nastavit pouze connection timeout a bohužel nelze nastavit data timeout. Pokud tedy daný server odpověděl, ale nedodával data dostatečně rychle nebo vůbec, thread se zasekl (test stahoval pouze jeden malý statický soubor, odezva by proto měla být rychlá). Během pár desítek minut se běžně stávalo, že takto viselo několik tisíc spojení a scan se extrémně zpomalil. Update: Requests umí oba typy timeoutů, zřejmě jsem to v dokumentaci přehlédl a trochu si zkomplikoval práci.
Oba typy timeoutů umí nastavovat URLlib 3, zkusil jsem tedy použít ji. U ní jsem nejprve narazil na drobný problém v tom, že jednoduše neprozrazovala URL cílové stránky po přesměrováních (do výsledků jsem započítával pouze cílové stránky - ohromné množství domén slouží pouze k přesměrování). To jsem však po chvíli studování dokumentace vyřešil (kód: retries.history[-1].redirect_location). Scan začal fungovat spolehlivěji, nicméně byl stále velmi pomalý a po krátké době navíc začala docházet i RAM.
Rozhodl jsem se tedy vyzkoušet (pro mě) novinku - asyncio a knihovnu aiohttp. To byl krok správným směrem. Získal jsem zhruba 20x rychlejší scan a rapidní snížení paměťových nároků. Problém byl u slabších strojů v tom, že nebyly schopny vytvořit 2 000 000 futures (úkolů), musel jsem tedy interně daný blok navíc dále rozkouskouvat na menší části dle schopností serveru (i slabá VPS zvládala 100 000). Scan se opět rozjel a brzy se objevila další komplikace, narazil jsem na limit otevřených souborů v základním nastavení linuxového jádra. Navýšil jsem limit a scanování se mohlo konečně rozjet naplno.
Během výzkumu jsem velmi často narážel na různé tarpity (speciální servery, které naschvál přijmou požadavek, ale již neodpoví žádnými daty - slouží jako nástrahy pro zpomalení scanů), nebo jednoduše pomalé servery. Častým problémem byla i geografická vzdálenost - snažil jsem se tedy ze seznamu vyčlenit některé geografické skupiny a ručně je spustit z blízkého datacentra - to jsem použil například pro Austrálii. Všechny tyto problémy se samozřejmě projevovaly při globálním scanu v mnohem větší míře než při menších lokálních výzkumech. Další komplikací byly různé honeypoty (nástrahy na detekci útoků), které mé servery posílaly na rozličné blacklisty a rozesílaly abuse stížnosti poskytovatelům VPS, se kterými jsem to následně musel řešit. I kvůli riziku zablokování jsem scan rozložil mezi několik poskytovatelů:
- Digital Ocean - zde běžela většina VPS, DO často využíváme pro své projekty
- Linode - velký podíl na scanu měly stroje tohoto poskytovatele, zde oceňuji aktivní práci security teamu, se kterým jsem komunikoval během řešení abuse, mají pro podobné projekty pochopení
- Hetzner - chtěl jsem je otestovat, ukázalo se, že za danou cenu poskytují velmi dobrý výkon
- BinaryLane - pro scan Austrálie
Celý scan trval prakticky 4 týdny a zhruba v polovině tohoto času jsem se rozhodl zdvojnásobit počet zapojených strojů - v největší špičce bylo do výzkumu zapojeno 18 VPS a 4 fyzické servery. Pro podobný scan je důležitá především dobrá konektivita a benefitem je více jader CPU.
Proč jsem nepoužil službu, jako je Amazon Lambda? Důvodem je, že jsem přesně nevěděl, co mne při scanování bude čekat za problémy a nedokázal jsem předem odhadnout náročnost. Nechtěl jsem být po provedení scanu nemile překvapen účtem za služby 🙂 Cenu VPS lze proti tomu vcelku jednoduše odhadnout. Celý scan vyšel zhruba na 250$ (bez fyzických strojů, které již máme).
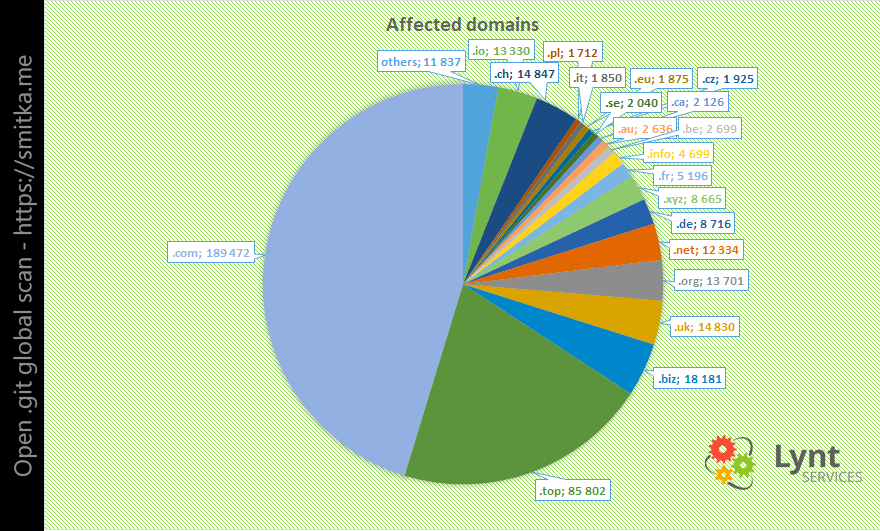
Výsledkem scanu bylo 390 000 webových stránek s otevřeným adresářem .git.
V druhé části scanu jsem tyto weby opětovně navštívil a vyhledal e-mailové kontakty ze souboru /.git/logs/HEAD. Ani zde samozřejmě nebyly vždy použitelné e-maily, přesto jsem takto získal 290 000 e-mailových adres svázaných s různým doménami. Ty bylo třeba dále zpracovat, protože mnoho kontaktů bylo asociováno s více než jednou doménou a několik z nich dokonce s více než 4000. Samozřejmě jsem nechtěl jednomu člověku posílat 4000 e-mailových upozornění, a tak jsem seznam agregoval dle e-mailové adresy a sestavil každému kontaktu seznam jeho domén, u nichž jsem ho objevil. Ze seznamu jsem dále vyloučil evidentně "strojové" adresy serverů, kde je minimální šance, že vůbec budou doručeny, natož přečteny. Touto operací vznikl seznam 90 tisíc unikátních e-mailů, na které jsem následně během týdne rozesílal upozornění. Pro podrobnější informace o chybě a možnostech její nápravy jsem připravil landing page smitka.me, na kterou jsem v e-mailu odkázal.
Nepodařilo se doručit zhruba 18000 e-mailů, protože již neexistovaly, nebo nebyly reálné. Dle zpětné vazby byla dále část e-mailů klasifikována jako spam, přestože při testech na mail-tester.com měly zprávy skóre 10/10 - pravděpodobně to bylo z důvodu většího množství reportovaných odkazů.
Po rozeslání e-mailů jsem si vyměnil dalších zhruba 300 dalších zpráv s postiženými stranami pro upřesnění problému. Obdržel jsem přes 3500 děkovných e-mailů, 40 upozornění na false positive, 3 obvinění ze spamu/scamu a jednu výhružku kanadskou policií a jedno udání na UOOU.
Po dokončení rozesílání následoval další výzkumný úkol - zjistit, na jakých technologiích jsou postižené weby postaveny. Pustil jsem tedy na nalezené weby nástroj WAD doplněný o aktuální definice z Wappalyzer (soubor apps.json). Tento nástroj bohužel již není příliš udržovaný, funguje jen v Python 2 a nemá moc dobře ošetřeny výjimky. Nemohl jsem mu tedy jednoduše předložit seznam domén k otestování, protože jediná chyba by měla za následek pád celé aplikace. Spustil jsem proto scany jednotlivě, ale s využitím nástroje parallel:
cat sites.txt | parallel -j 20 --bar --tmpdir ./wad --files wad -u {} -f csv
Velkou pomůckou byl pro mne také emulátor terminálu a správce relací MobaXterm. Na GitHub jsem umístil několik ukázek skriptů, které jsem pro scan použil.
Výsledky
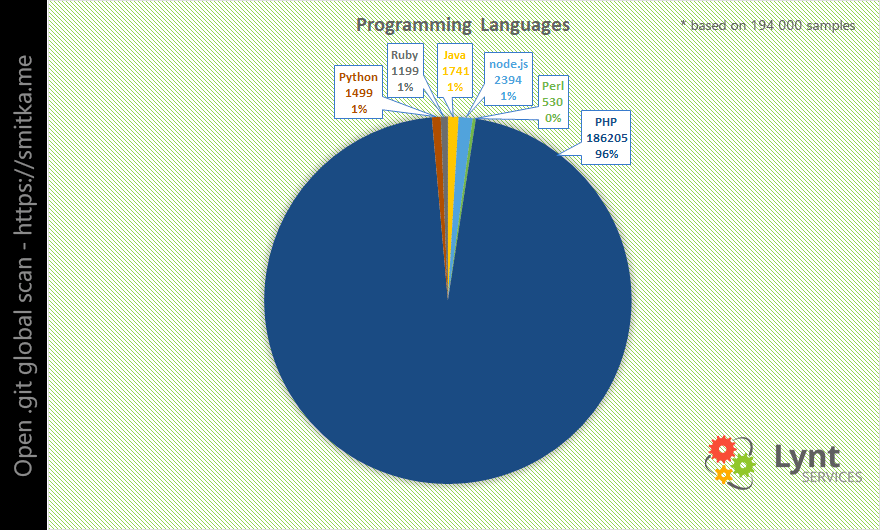
Nejrozšířenějším jazykem pro tvorbu webů je PHP, takže se dalo čekat, že nejvíce postižených webů bude využívat právě ten.
Velmi zajímavá čísla dostaneme, pokud tyto výsledky znormalizujeme podle zastoupení jednotlivých jazyků (podle W3techs):
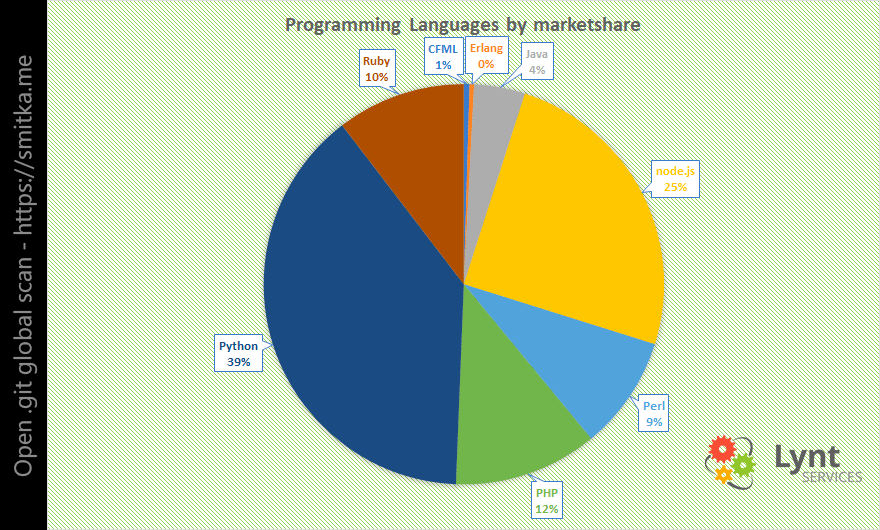
Pokud by bylo zastoupení všech jazyků stejné, tak by nejhorší situace byla u Python vývojářů a PHP bylo až na 3. místě.
Dále mě zajímalo, jaké HTTP servery a operační systémy weby používají:
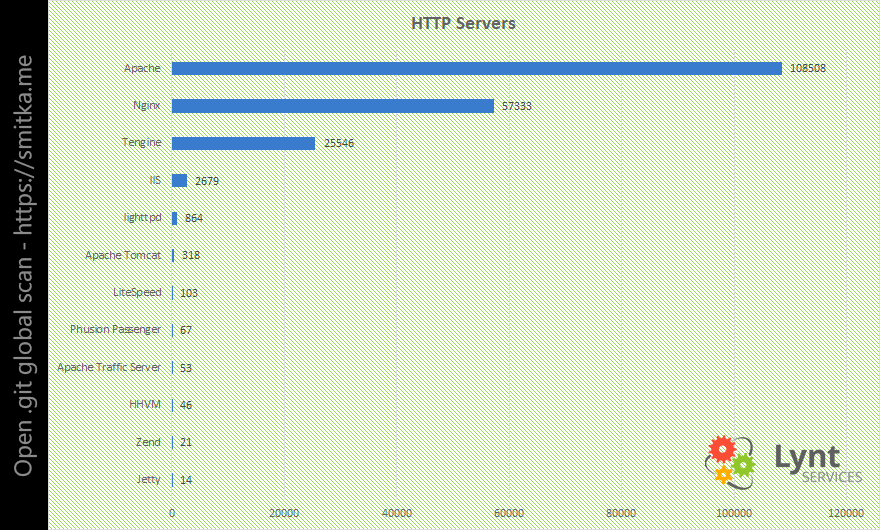
Byl jsem překvapen zastoupením serveru Tengine (čínský fork Nginx).
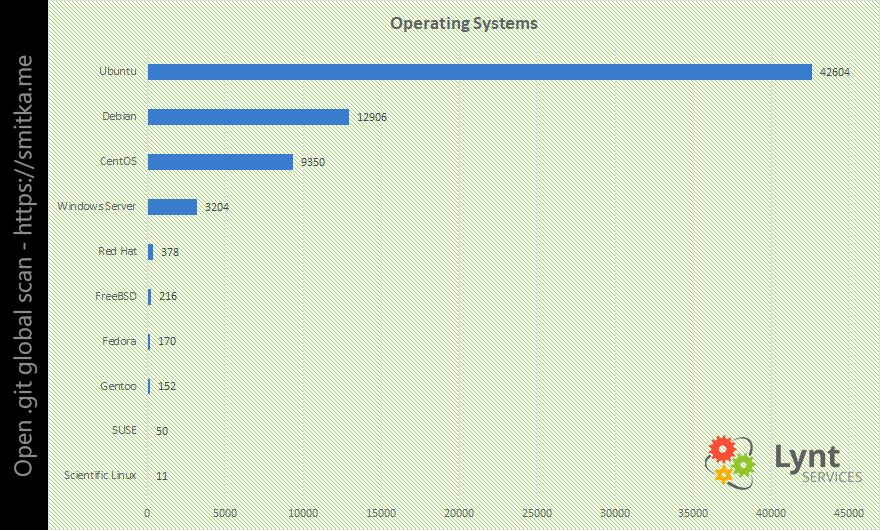
Mezi operačními systémy samozřejmě vede Linux a v něm distribuce Ubuntu. Můj oblíbený CentOS je na 3. místě.
V poslední části přehledu jsem se zaměřil na použité CMS, e-shopová řešení a aplikační frameworky.
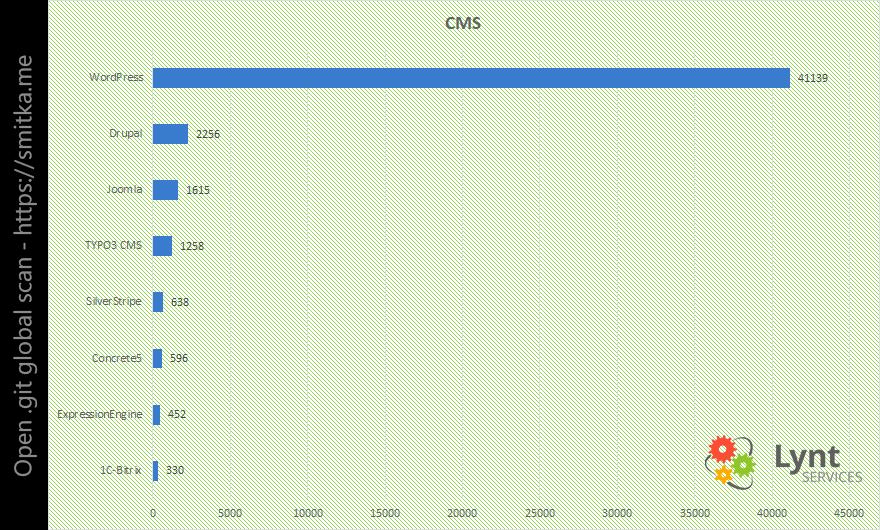
Není překvapením, že WordPress v této kategorii dominuje. Pouze zhruba 12% těchto WP webů používá poslední minor verze s bezpečnostními záplatami. Může to být proto, že když WP detekuje složku .git (nebo jiný VCS), tak vypne automatické aktualizace jádra a nechá starost s nimi na vývojáři. S posledními verzemi je situace obdobná i v případě CMS Drupal a Joomla - většinou se jedná o starší verze.
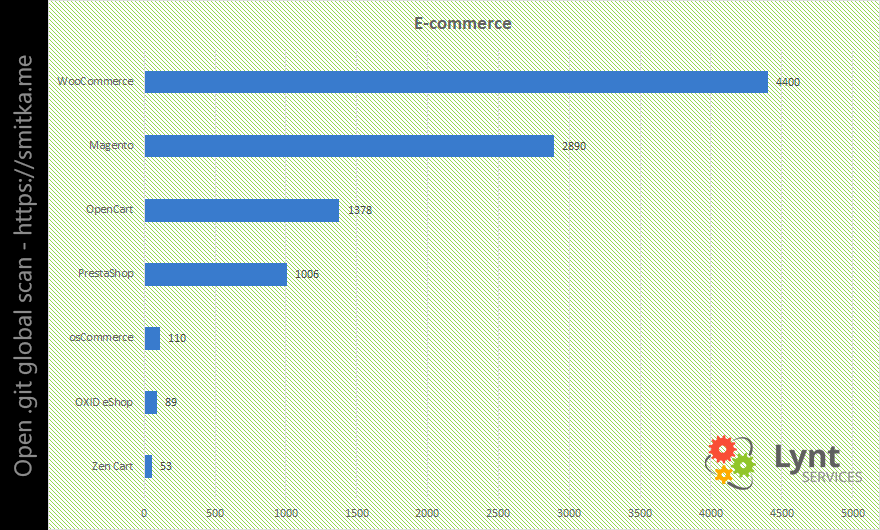
Obdobně jako v předchozím případě je tomu i ve světě e-commerce. WordPress plugin WooCommerce je nasazen na většině postižených e-shopů.
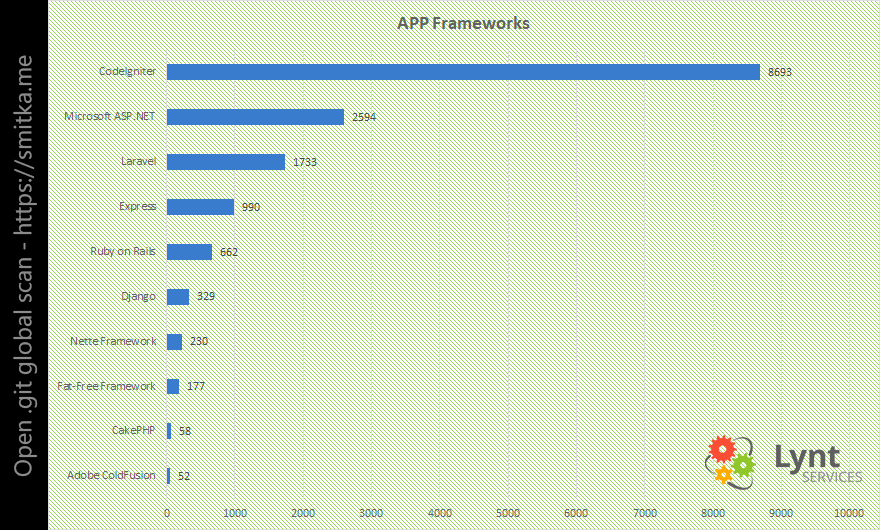
Detekce frameworku je často složitější, mnoho z nich o sobě nedává znát. V některých případech se však framework detekovat podařilo a ukázalo se, že nejvíce postižených stránek v této kategorii používá CodeIgniter.
V dalším plánu je provedení opětovné kontroly po několika týdnech a pokus o znovukontaktování tvůrců. Kontrolovat se bude mnohem menší dataset, a tak chci přidat 2 funkce pro redukování false positive:
- kontrolu, zda je veřejně dostupný hash commitu na githubu pro veřejné repozitáře
- prověření indexu, zda repozitář obsahuje dynamické soubory, abych vyloučil například různé statické landingpage
Závěrem bych chtěl všem doporučit více hlídat, co nahráváte do svého webového prostoru - nejedná se jen o verzovací systémy, ale například i o různé dočasné testovací skripty. Je dobré také pamatovat na to, že se věci mění - konfigurace serveru i členové týmu. To, co se dnes nezdá být problémem, jím může zítra být.
Souhrn k 12/2018:
- 230 000 000 webů oscanováno,
- 390 000 webů postiženo,
- přes 100 000 notifikací developerům odesláno,
- přes 150 000 webů bylo opraveno 2 měsíce od nahlášení,
- nalezen další kritický problém s chybně nakonfigurovanými webovými servery, postihující tisíce dalších webů,
O problematice jsem přednášel na konferenci OpenAlt v Brně 11.3.2018 - slidy, video.
A jako vždy, děkuji Báře za jazykové korekce.

super práce
Skvělá akce!
"2000 děkovných e-mailů" - boží 🙂
> Po dokončení rozesílání následoval další výzkumný úkol - zjistit, na jakých technologiích jsou postižené weby postaveny.
Skoro se bojim nebo to zas schytam (docker je prece dokonaly), ale bylo by zajimave videt kolik z toho byl "docker za 5 minut", "nastavim na adresar, nic neresim a zapomenu".